中国大学MOOC(慕课):厦门大学-林子雨-《大数据技术原理与应用》笔记,第二部分。
持续更新。
第7章 MapReduce
MapReduce是一种分布式并行编程框架。CPU算力的摩尔定律,每18个月翻一番,15年开始失效。大数据摩尔定律继续。解决大规模数据处理的两条途径:增加CPU的核心数量,分布式并行编程。于传统的并行编程框架(MPI,OpenCL,CUDA)的区别:集群的架构和容错性(传统的是共享式,共享内存,共享底层存储空间),硬件价格及扩展性(传统的为刀片服务器),编程和学习难度(传统的要自己实现多线程的编程,要借助很多互斥信号量和锁等),适用的场景(适用于实时的细粒度的计算,计算密集型的应用,MapReduce适合非实时的批处理以及数据密集型的业务)。
计算向数据靠拢,而不是数据向计算靠拢。并非由计算节点拉取所需要的的数据,而是由数据选择最近的计算节点计算。Map函数,输入一个键值对,输出一系列键值对,是计算的中间结果。Reduce函数,输入键,值列表的对,对其汇总求和,输出一个键值对。
体系结构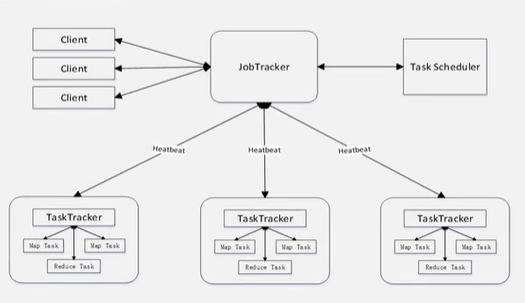
工作流程
一个文件在HDFS中以分布式的方式存储于多个块(物理上),由InputFormat分为另若干个片(用户定义,逻辑上),一般以物理块的大小确定分片的大小(避免数据物理上多次传输),Map任务数量决定于分片的多少,Reduce任务数量决定于集群中可用的Reduce任务槽(slot)(稍少,预留于错误处理)。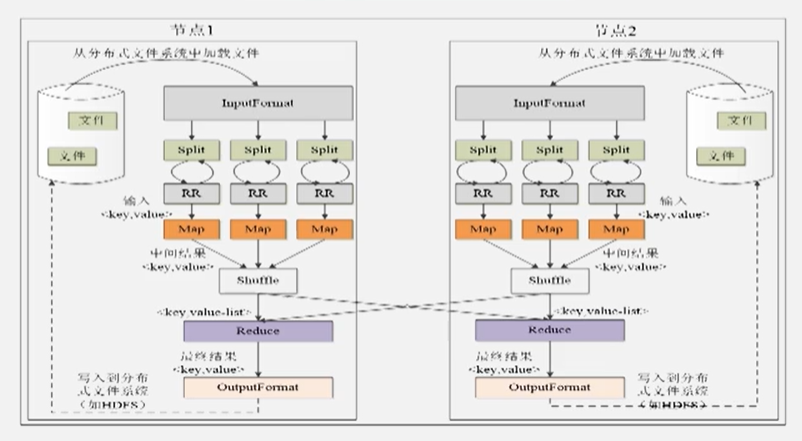
Shuffle过程原理
Map端的Shuffle过程,输入,输出键值对,写入缓存,超过阈值(80%)后,分区,排序(默认),用户自定义合并(Combine),归并为一个大文件。通知对应Reduce端取数据。Reduce端的Shuffle任务,取多个Map端的数据后,先归并,然后进行可能的自定义合并,然后给Reduce处理。
MapReduce应用程序执行过程
用户程序——程序部署(一个Master,多个Worker分别执行Map&Reduce任务)——对单个大文件进行分片(执行Map的Worker中有空闲的机器)——读数据,生成键值对——执行Map任务,生成大量键值对——写入缓存,若满,分区排序合并,溢写到磁盘——Reduce机器拉取数据,完成数据处理——写出到HDFS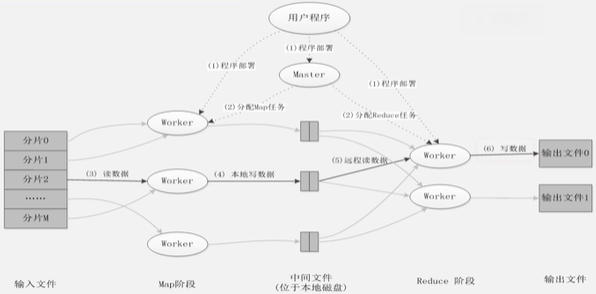
WordCount词频统计实例
只有特定的任务(可以分而治之,互不依赖)可以使用MapReduce来计算。词频统计是一个非常典型的场景。
MapReduce应用
关系代数运算,矩阵运算,矩阵乘法,分组聚合等。自然连接的实现。
第8章 Hadoop再探讨
早期的Hadoop抽象层次低(简单的任务仍然需要写出完整的Map和Reduce函数),表达能力有限(实际的问题又很难只是用Map和Reduce来简化),开发者要自己实现作业之间的相互依赖。难以看到程序整体的逻辑,执行迭代操作的效率比较低(每次中间的结果都要存在HDFS中),资源浪费(严格划分Map阶段和Reduce阶段,阶段之间的异步浪费了时间),实时性差。
Hadoop的改进:对自身的核心组件改进,HDFS和MapReduce的改进。添加额外其他的组件。针对HDFS的单一名称节点可能会失效的问题,设计了HDFS HA提供热备份;针对HDFS单一命名空间无法实现资源隔离的问题,设计了HDFS Federation管理多个命名空间;针对MapReduce资源管理效率低的问题,设计了新的资源管理的框架YARN。
另:设计了Pig作为大规模数据的脚本语言,类似SQL语句,自动转换为MapReduce作业;设计了基于内存的分布式并行编程框架Spark,具有较高的实时性,并且较好的支持迭代计算;设计了Ooize作为工作流和协作服务引擎,协调Hadoop上运行的不同任务;设计了Tez作为DAG作业的计算框架,对作业的操作进行重新分解和组合,形成一个大的DAG图,减少不必要的操作;设计了Kafka,分布式发布订阅消息系统,一般作为企业大数据分析平台的数据交换的枢纽,不同类型的分布式系统可以统一的接入到kafka,实现和Hadoop各个组件之间的不同类型数据的实时高效交换。
HDFS HA和HDFS Federation
活跃的名称节点和待命的名称节点共享存储系统,实时同步(EditLog),而数据的映射信息由数据节点同时向两个节点进行汇报。由心跳机制向Zookeeper保持联系,控制名称节点的实时工作,一旦故障立即转移。HA实际上就是一个热备份,解决单点故障的问题。
还有其他的问题无法解决:不可以水平扩展,整体性能受限于单个名称节点的吞吐量,不同程序之间的隔离性。引入HDFS Federation。多个名称节点,有逻辑上的块池,但是共享数据节点。
YARN
MapReduce1.0中存在的缺陷:单点故障(只有一个Job Tracker),单点任务过重,容易内存溢出(不对任务所需要的资源设限),资源划分不合理(资源独立的划分给Map slot和Reduce slot。
架构的基本思路:ResourceManager(处理客户端请求,启动/监控ApplicationManager和NodeManager,资源分配及调度,全局的资源管理,以容器的形式动态的分配),ApplicationMaster(为应用程序向ResourceManager申请资源,对任务的调度,监控和容错)、NodeManager(每个YARN集群节点的资源的管理)
YARN的目标是实现一个集群多个框架。如果不同计算框架有多个资源调度管理功能,会造成冲突和资源浪费。
Hadoop生态系统中的代表性组件
Pig:程序员编写Pig Latin语句(类SQL)由Pig引擎转化为MapReduce程度。面向技术人员,适合即时性的数据处理需求,可以通过几行脚本语句快速生成。
Tez:支持DAG作业的计算框架。把Map和Reduce任务进一步拆分,可以去除两个作业之间写入磁盘的过程,并且去掉多余的Map任务等。底层HDFS,YARN,Tez,(MR,Pig,Hive)。优化MapReduce任务。
Spark:MapReduce延迟非常高,无法实时计算,中间结果写入磁盘,并且前一个任务执行完之前,其他的任务无法开始,难以胜任复杂多阶段的任务。Spark采用内存计算,适合迭代结算,基于DAG的任务调度机制。
kafka:高吞吐量的分布式发布订阅消息系统,同时满足在线实时处理和批处理。在企业大数据系统中起到数据交换中枢。