中国大学MOOC(慕课):厦门大学-林子雨-《大数据技术原理与应用》笔记,第一部分。
持续更新。
第1章 大数据概述
信息化浪潮:1980年前后,个人计算机。1995年前后,互联网普及。2010年,物联网,云计算和大数据。存储(单位存储的价格不断下降),计算(CPU处理能力大幅增加),网络(带宽不断增加),数据产生的方式不断变化。
概念,影响及应用:4V:大量化(大数据摩尔定律),快速化(响应时间要快),多样化(结构化和非结构化数据),价值密度低(商业价值高)。全量而非抽样,效率而非精确,相关而非因果。应用例子:大数据影响影视剧投拍决策,大数据预测流感趋势。
关键技术:数据采集,数据存储与管理,数据处理与分析,数据隐私和安全。分布式存储&分布式处理,单机无法存储也无法处理,利用计算机集群。分布式数据库(BigTable),分布式文件系统(GFS),分布式并行处理技术(MapReduce)。不同的计算模式服务于不同的应用:批处理(MapReduce,另Spark适合迭代式计算例如数据挖掘,实时性不行),流计算(S4,Storm, Flume,针对流数据的实时计算,需要实时计算给出结果),图计算(Google Pregel),交互式查询分析计算(Google Dremel,Hive,Cassandra)。
大数据,云计算和物联网的关系:云计算:解决了海量数据的分布式存储和分布式计算的问题。典型特征:虚拟化,多租户。公有云(百度网盘,面对全国用户),私有云(企业内部),混合云。Iaas:基础设施即服务,将基础设计(计算和存储资源直接作为服务出租)。PaaS:平台即服务。SaaS:软件即服务,例如云财务软件。云计算数据中心,刀片式服务器,集群。数据中心的能耗非常大,绝大多数用于散热。所以建在地址稳定,气温低的地方。物联网(The Internet of Thing,IoT):感知层(各类传感器),网络层(信息传输的通道),处理层,应用层(掌上智能公交)。物联网的关键技术:感知,识别。
第2章 大数据处理架构Hadoop
2.1 简介和版本演变
Hadoop是Apache软件基金会旗下的开源软件(项目)。Hadoop是用Java开发的,但是支持多种编程语言。Hadoop的两个核心:HDFS(分布式文件系统,是2003年谷歌提出的分布式文件系统GFS的开源实现) + MapReduce(分布式并行编程框架,谷歌2004年提出)。高可靠性(冗余集群),高效性(并行计算),高扩展性,成本低(除了高性能计算机,可以用普通的PC机构成集群),支持多种编程语言。
访问层:数据分析(离线分析,批处理),数据实时查询,数据挖掘。
大数据层:高级分析(Hive(数据仓库),Pig,MapReduce),实时查询(Solr,Redis,Hbase(分布式存储数据库)),BI分析(Mahout(数据挖掘,机器学习等算法的集成))。以上的底层是HDFS分布式文件存储。
最后是数据源。
Hadoop不同版本的问题:主要有1.0和2.0两个版本。最主要的差别:1.0中有两个核心部分,HDFS分布式文件存储系统,以及MapReduce并行计算框架(包含数据处理部分和集群的资源调度)。其中MapReduce涉及到的任务太多了,所以效率低下。在2.0中,把MapReduce的功能分开了,把其对资源的调度功能划分出来做成一个新的框架YARN,做整个资源调度(CPU,内存,带宽)。MapReduce则只做数据分析,相当于在架构在YARN调度框架上的一个应用。YARN还可以支持其他的计算框架,例如Storm,Spark。HDFS增加了NameNode(NN Federation)(便于扩展),High Availability(容灾)。
另外还有不同的商业发行版,企业推荐cloudera,各方面最好,个人用开源版。
2.2 Hadoop项目结构
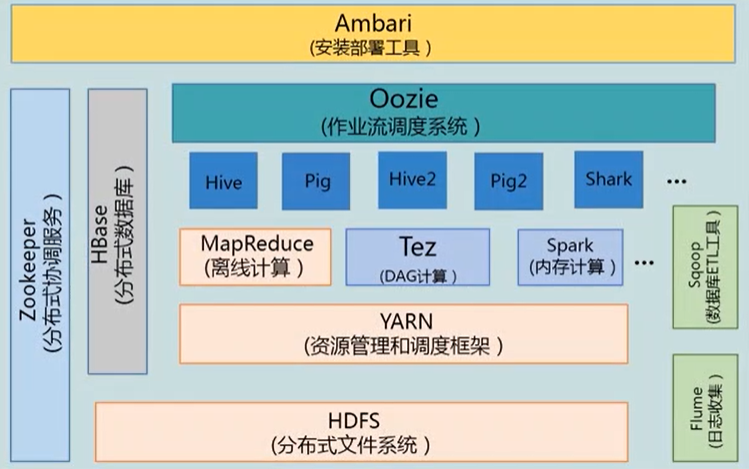
要理解各个部分的功能。
Linux和Hadoop的安装:Hadoop3.1.3安装教程_单机/伪分布式配置_Hadoop3.1.3/Ubuntu18.04(16.04)。
这个教程非常良心,步骤详细清晰。
hadoop集群的部署和使用:Hadoop集群安装配置教程_Hadoop3.1.3_Ubuntu。
NameNode,DataNode,JobTracker,TaskTracker,SecondaryNameNode的架构,各节点的硬件要求,不同场景下架构的变化。
第3章 分布式文件系统HDFS
Hadoop Distributed File System, HDFS
HDFS实现目标:兼容廉价的硬件设备,实现流数据读写,支持大数据集,支持简单的文件模型,强大的跨平台的兼容性。HDFS自身的局限性:不适合低延迟的数据访问,无法高效的存储大量的小文件,不支持多用户写入以及任意的修改文件。
相关概念
数据块,HDFS中的块非常大,支持大规模文件存储,简化系统设计,适合数据备份。名称节点,存储元数据,核心结构为FsImage(保存系统文件树)和EditLog(文件操作),FsImage和EditLog之间信息的合并在SecondaryNameNode中。数据节点,实际存储数据。
体系结构
1.0中为单点通信,瓶颈在于名称节点和数据节点之间的信息传输速率,并且容错率较低,SecondaryNameNode为冷备份,同时名称节点的内存大小限制了总的结点数量,隔离问题,不同应用公用同一个NameNode。2.0中对以上的问题做了修复。
存储原理
主要关注三个问题:冗余数据的保存(加快传输,检查错误,可靠性),数据保存的策略(谁发起谁存储,错开机架,随机分布,读取的时候优先选同一个机架),数据恢复的问题(名称节点出错调用备份,数据节点定期应答保证正确,校验码保证数据正确)
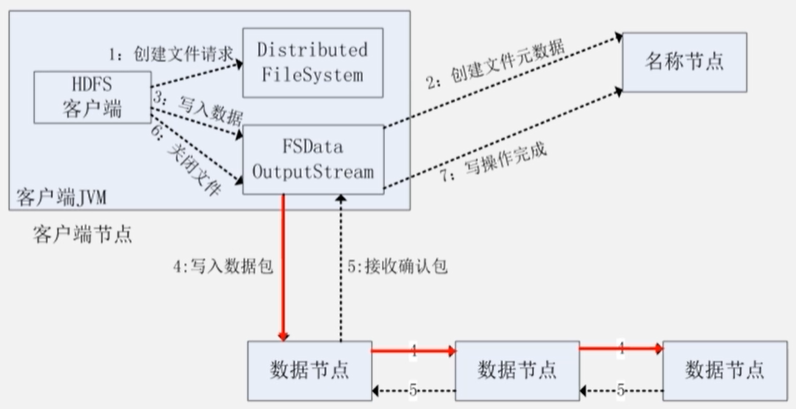
读写过程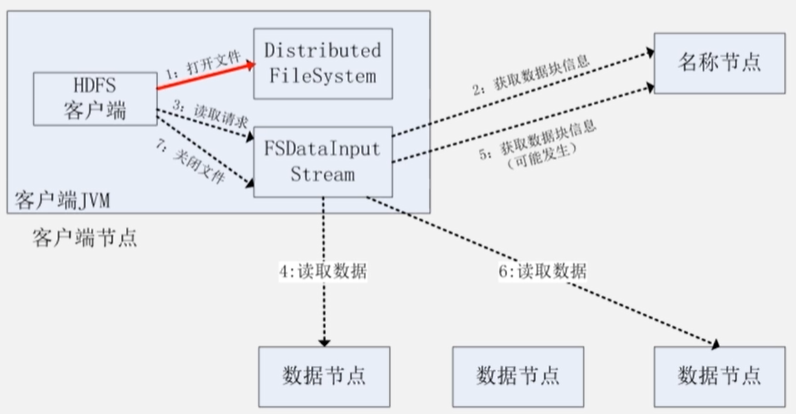
1 | cd /usr/local/hadoop |
利用Linux Shell命令与HDFS进行交互,最常用的是fs,可以查看HDFS文件系统的目录结构、上传和下载数据、创建文件等。。
1 | ./bin/hadoop fs #查看支持哪些命令 |
第4章 分布式数据库Hbase
Hbase是BigTable的开源实现,最初用于解决Google内部的网页搜索问题,例如对爬虫爬下来的网页建立索引等。HDFS对应GFS,Hadoop MapReduce对应MapReduce,ZooKeeper对应Chubby。高可靠,高性能,面向列,可伸缩,存储非结构化和半结构化的松散数据。
Hbase存在的必要性:实时性,可拓展。Hbase和传统的的关系型数据库的联系和区别:数据类型(未经解释的字符串&关系数据模型),数据操作(避免多表连接&各类连接操作),存储模式(列&行),数据索引(行的简单索引&针对列的复杂索引),数据维护(数据按版本存在&数据覆盖),可伸缩性(高扩展性&难以水平扩展)。
Hbase访问接口:原生Java API:Shell命令、Thrift Gateway、REST Gateway;SQL类型的接口:Pig、数据仓库产品Hive。
数据模型
稀疏的多维度的排序的映射表。
行键、列族、列限定符号、时间戳。每一个值都是未经解释的字符串,编程人员自行解释。概念来看,每行为一个对象,每列都是一个特征,比较特殊的特征是列族、列限定符号、时间戳,这个所有的都存在,对Hbase中每个值的索引都需要这几个维度(传统的关系型数据库是二值索引)。但是从实际实现上来看,是按列存储。
按行存储和按列存储的差别:按行存储可以很快得到某个对象所有的值,但是对于空值比较多的会造成很大的浪费,同时不便于集中分析某一个特征。按列存储由于数据类型相似,可以得到很高的数据压缩率。事务性操作比较多,按行,对于数据分析比较多,按列。
实现原理
Hbase的功能组件:库函数(链接每个客户端,便于客户端访问),Master(分区信息的维护和管理,Region的服务器列表,Region分配,负载平衡),Region服务器(存储Region,客户端不依赖Master)。Region过大后会被拆分,Region的定位方法:ZooKeeper文件,-ROOT-表(不分裂),元数据表(Region id,服务器id)即.META.表(过大会分裂) ,用户数据表
运行机制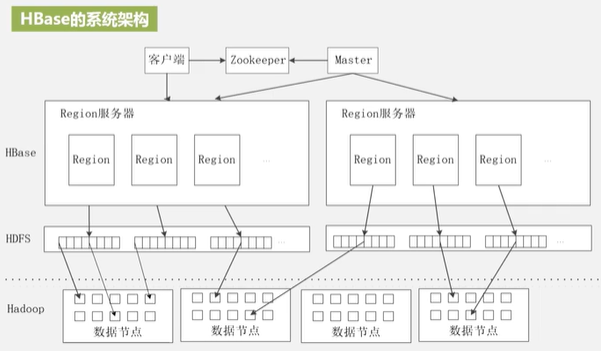
写入数据——写缓存MemStore——写HLog——读数据——读MemStore——读磁盘StoreFile。
应用方案
性能优化方法:时间靠近的数据存在一起(按时间戳排序)、设置是否放入内存、设置最大版本数量、检测性能(Master-status、Ganglia、OpenTSDB)。
利用Hive(或者Phoenix)整合Hbase,提供SQL接口。
构建二级索引。利用Coprocessor构建二级索引。等。
1 | cd /usr/local/hbase |
第5章 NoSQL数据库
Not only SQL,非关系型数据库,特定:灵活的可扩展性,灵活的数据模型,适合云计算。传统的关系型数据库没法满足海量数据的管理需求,无法满足高并发的需求,无法满足高可扩展性和高可用性的需求。
NoSQL数据库和关系数据库的比较
没有关系数据库的完备的关系代数的理论基础,但是具有很好的水平可扩展性,不用定义严格的数据库模式,数据模型非常灵活。另关系型数据库在适当的数量级的查询效率高,但是数据量级增大的话查询效率就会下降,NoSQL数据库则并没有构建面对复杂查询的索引,性能差。事务一致性,关系型数据库遵循ACID事务模型,保证了事务强一致性,NoSQL只保证最终一致性。关系型数据库具有保证完整性的完备的机制,NoSQL不能实现完整性的约束。NoSQL拓展性更好。关系型数据库严格保证一致性,规模增大后可用性差,NoSQL可用性很好。关系型数据库的标准化很完善,NoSQL目前没有没有行业通用的标准,有很多的类别。NoSQL维护更为复杂。
四大类型NoSQL数据库
键值数据库:Redis,数据模型就是键值对,键是字符串对象,值是任意类型的数据。适合频繁读写,简单的数据模型的应用,内容缓存,会话,配置文件,参数,购物车等。优点是扩展性好,灵活性好,大量的写操作的新能高。缺点是无法存储结构化的信息,条件查询效率低,不能对值作索引。不适合需要对值查询,不适合存储关系化的数据。实际上多数用来作为网页应用缓冲层的解决方案。
列族数据库:Hbase,数据模型就是列族,适合分布式的海量数据存储和管理,优点是查找速度快,可扩展性强,容易进行分布式扩展。缺点是功能少,不支持强事务的一致性,不适用需要ACID事务支持的情形。
文档数据库:MongoDB,本质上也是键值数据库,但是值是文档,能将自己的数据和类型进行自我描述。文档数据库的数据结构:JSON数据格式,具有更好的并发性,对数据进行更新时,只需要更新一个文档即可。优点是,性能好(高并发),灵活性高,提供嵌入式文档功能,确定是缺乏统一的查询语法。文档间不支持事务机制。
图数据库:Neo4j,基于图结构,优点是灵活性高,支持复杂的图形算法,用于构建复杂的关系图谱。 缺点是应用范围有限。专门用于处理有高度相关关系的数据,例如社交网络。模式识别,依赖分析,推荐系统以及路径寻找的问题。
NoSQL数据库的理论基础
CAP理论:Consistency,任何一个读操作都能够读到之前完成的写操作的结果。Availability,快速获取数据,可以在给定的时间内返回操作的结果,保证每个请求不管成不成立都有响应。Partition tolerance,出现网络分区的时候,分离的系统也能够正常运行。一个分布式系统不能同时满足三个性质。
BASE:Basically Available(基本可用,一部分不可用时,其他的部分还是可用的),Soft-State(状态可以有一段时间的不同步,具有一定的滞后性),Eventual consistency(高并发的数据访问的操作下,后序操作能不能获取最新的数据,因果一致性:某个进程被通知更新了,则会读到新的数据;读己之所写一致性:自己执行的更新操作后,后序都可以访问新的数据;单调一致性:进程已经看到过数据对象的某个值了,则任何的后序访问都不会返回之前的旧值;会话一致性:把访问存储的进程放到会话当中,只要会话存在,就保证读自己所写的一致性;单调一致性,保证来自同一个进程的写操作按顺序执行)。W(写进程要写入的节点数)+R(读进程读到的节点数)>N(数据节点数)可保证强一致性,<=N可保证弱一致性,N=W,R=1保证强一致性,但是任何一个节点写入失败则失败,会导致弱可用性。对于Hbase借助底层的HDFS实现数据的冗余备份,HDFS采用强一直性,只有数据完全同步到N个节点,写操作才会返回。
从NoSQL到NewSQL
OldSQL:一种架构支持多种应用,无法实现。分析性应用(NewSQL),事务性应用(OldSQL),互联网应用(NoSQL)。
MongoDB
C++编写的分布式文件存储的开源数据库系统。高负载的情况下添加更多的结点保证服务器性能。旨在为WEB应用提供可扩展的高性能数据存储解决方案。与传统的关系型数据最为相似。类JSON的键值对的二进制文档。能支持对任何不同的属性进行索引等优点。
第6章 云数据库
云计算,通过网络以服务的方式为客户提供廉价的计算资源,有按需服务,随时服务,通用性,高可靠性,极其廉价,高可扩展性等的优点。